

This project was completed with another group partner as part of our Machine Learning course. The goal was to analyze a public dataset to determine different components that affect the quality of red wine compared to white wine. We used Python as our main tool to run various models on the dataset, create data visualizations, and extract the most relevant predictors.
.png)
Our various models are listed below, with the smallest Mean Squared Error in green, and vice versa for red.
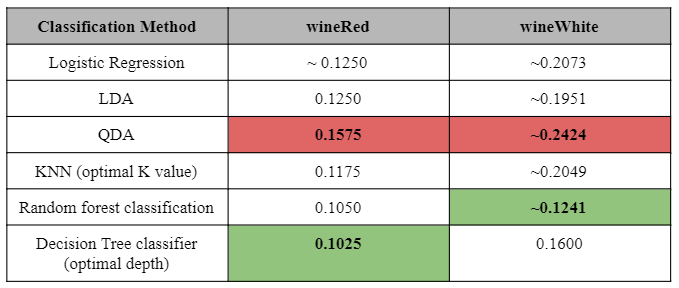
As can be seen, the decision tree classifier was the best model for red wine while random forest classification was best for white wine.
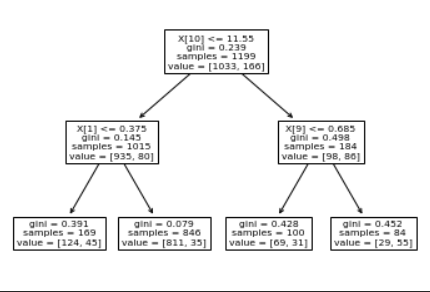
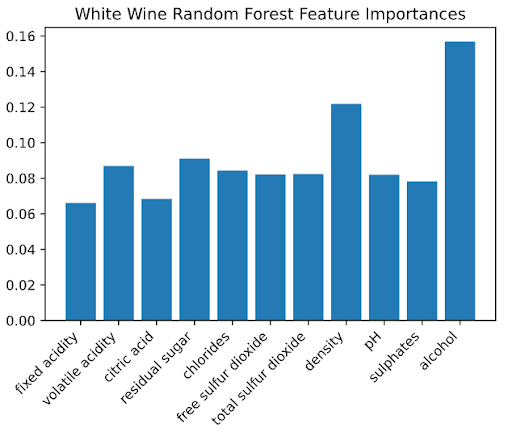
From our analysis, we found that alcohol was by far as the most significant predictor of red wine quality, followed by volatile acidity. On the other hand, we found alcohol and density to be the most important predictors of white wine quality.
For further details on our analysis, view the full report here with all of our findings.

{kind=link}